Topic = DB 를 설계, 정규화 하는데 필요한 FD, Key, Prime Attribute 개념을 정리해보자.
- 목차 -
1. 정규화를 적용하지 않아 발생할 수 있는 update anomaly 를 알아보기.
2. 정규화를 진행하기 위해 알아야 하는 FD 개념 알아보기.
3. Key의 분류와 프라임, 논 프라임 속성 분리 기준을 알아보기.
정규화 적용 및 정리는 정규화 [ 2 ] 에서 작성하기.
정규화란?
정규화는 관계형 데이터베이스( RDBMS ) 에서 데이터의 중복을 줄이고, 데이터가 관심사 별로 처리되도록 테이블을 쪼개 성능을 향상 시키는 활동이며
이 작업은 update anomaly (이상 현상) 를 최소화 하여 데이터 무결성을 유지하는 것을 목표로 일련의 normal form ( 정규형 ) 에 따라 테이블을 구조적으로 조직하는 과정으로 진행된다.
➡️ 정규화 작업은 입력 / 삭제 / 수정의 성능은 향상되지만, 조회 성능은 향상될 수도, 저하 될 수도 있다.
Update anomaly ?

- update anomaly는 정규화가 되지 않은 RDBMS 테이블에 데이터 쓰기 작업 시 발생할 수 있는 문제를 말한다. 이는 데이터 삽입 ( insertion ), 수정 ( modification ), 삭제 ( deletion ) anomaly로 세분화 할 수 있다.
- 위 사용자와 그룹 정보를 담고 있는 테이블을 통한 예시를 통해 update anomaly 상황을 정리해볼 것이다.
[ Insertion anomaly ]
- 테이블에 새로운 tuple을 삽입할 때, 특정 속성의 값이 존재하지 않아 불필요하게 null 값을 삽입하는 등 데이터 삽입 시 발생하는 문제
📜insertion anomaly e.g.
🟥 case1. 불 필요한 null 데이터
새로운 그룹 또는 사용자를 추가할 때, 사용자 속성에 해당하는 필드를 NULL로 채워두고 생성을 하게 된다. 값이 null인 데이터가 늘어남으로 인해 유지 관리시 복잡도가 올라가는 문제가 발생할 수 있다.
🟪case2. 중복된 데이터
하나의 테이블에서 사용자와 그룹을 관리하기 때문에, 데이터 중복이 발생한다. 이는, 저장 공간 낭비 문제가 발생한다.
🟨 case3. PK 값의 부조화
그룹을 저장하는 목적의 tuple을 별도로 만들어주어야 하는데, PK 값은 NULL로 지정할 수 없다. 이로 인해 PK로 지정된 Attribute 이름의 의미에 부적합한 tuple이 존재하게 되는 문제가 발생한다.
[ Deletion anomaly ]
- 특정 데이터를 삭제할 때, 원하지 않는 다른 데이터도 함께 삭제되는 문제
📜deletion anomaly
insertion anomaly 예제에서 그룹 데이터를 추가하기 위해 사용자 정보가 NULL 인 그룹 tuple을 작성했는데, 해당 그룹에 사용자가 들어왔을 때, 더 이상 기존의 사용자가 null 인 그룹 데이터 tuple 을 유지하지 않아도 되기 때문에 아래와 같이 기존 tuple 을 지워줄 수 있게 된다.
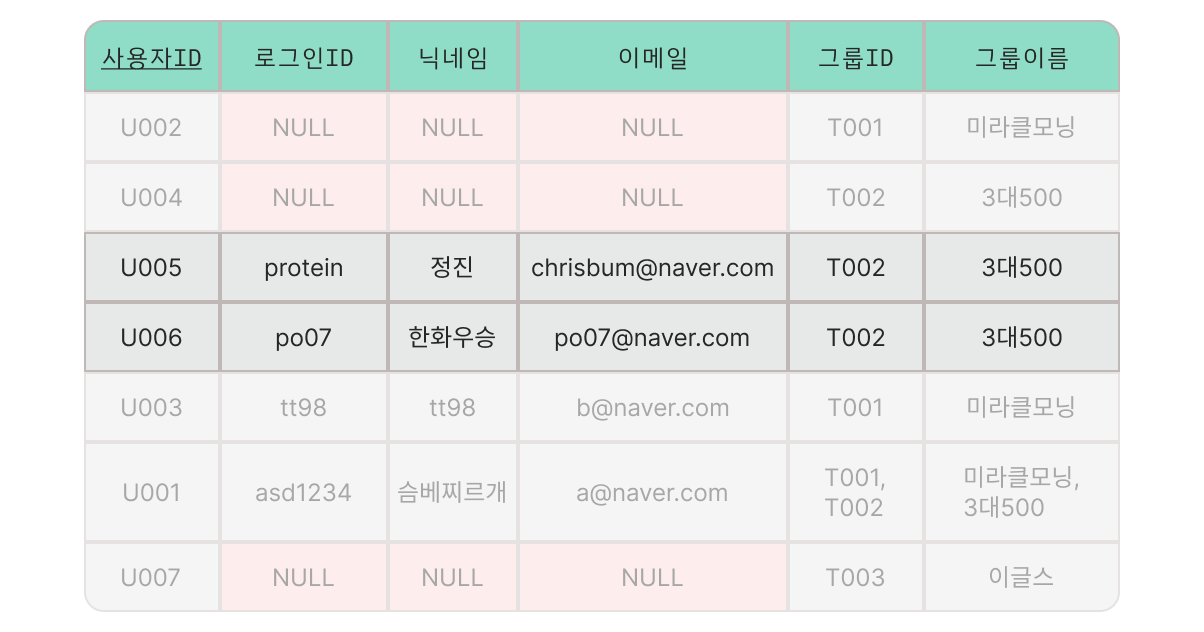
⬜ case 1
만약 위와 같은 상황에서 tt98 사용자와 asd1234 사용자가 탈퇴를 하여 해당 사용자의 데이터를 삭제하게 된다면, 미라클 모닝 그룹 자체의 데이터가 사라지게 되는 문제가 발생한다.
[ case.1 result ]
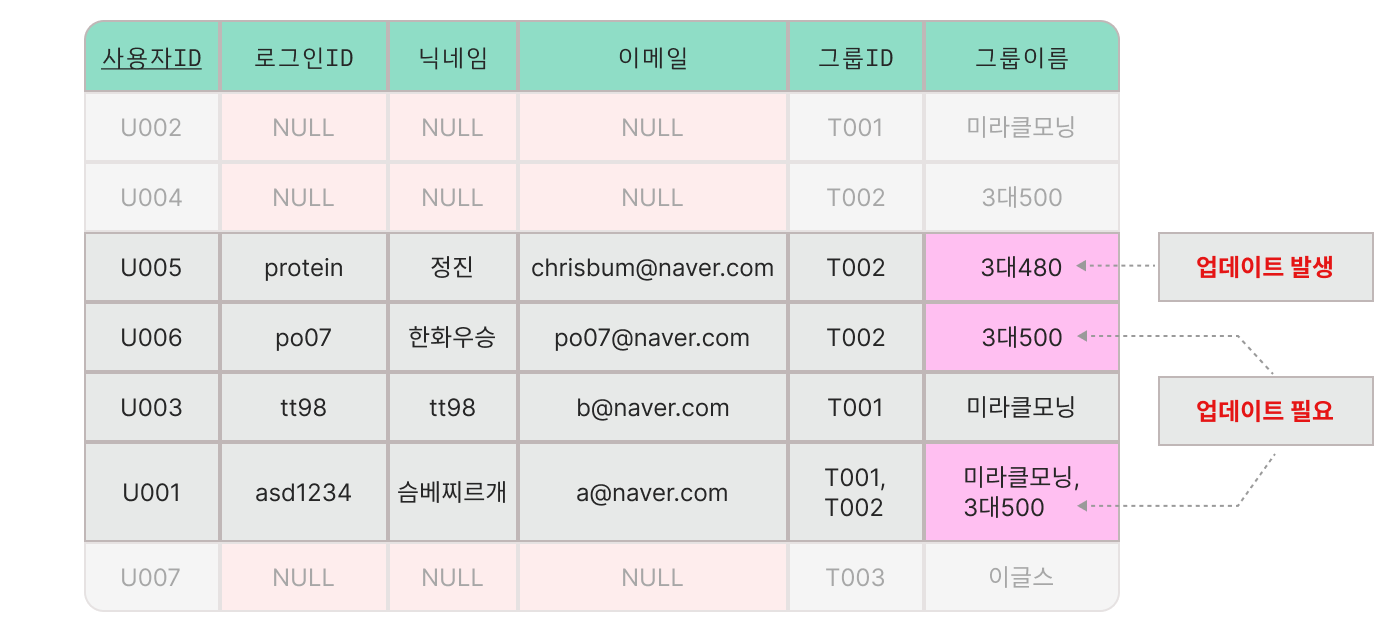
[ modification Anomaly ]
- 하나의 데이터 값에 변경이 일어날 때, 데이터의 무결성이 깨지는 문제가 발생하여 관련된 모든 데이터 값을 변경해주어야 함으로 데이터 베이스 성능이 저하되는 문제.
FD - Functional Dependency 함수적 종속성
- FD란, 한 테이블에 있는 두 속성의 집합 사이의 제약이다.
- 어떤 제약일까? => X 값에 따라 Y 값이 유일하게 결정되는 X, Y 집합을 얘기한다.[X는 결정자, Y는 종속자 이다.]
학생 정보를 저장하는 테이블의 경우, PK로 지정된 학생 ID 에 해당하는 학생 이름을 식별할 수 있게 된다. X{ stu_id } → Y{ stu_name } 의 종속성이 성립이 되는 것이다. 반대로 stu_name 은 동명이인의 학생이 존재할 수 있기 때문에 X → Y 일 때, Y → X 는 참일 수도 있고, 아닐 수도 있다. - X → Y 와 같을 때, 다음과 같이 표현할 수 있다.
- ➡️X가 Y를 함수적으로 결정한다.
- ➡️Y가 X에 함수적으로 의존한다.
- 테이블의 특정 상태만 보고 X → Y 의 종속성을 파악해서는 안된다.
- 예를 들어, 상품 재고 관리를 하기 위한 테이블이 있을 때, 상품 이름이 슈크림 빵인 데이터의 제조사는 A만 존재했기 때문에 X { 상품이름 } → Y { 제조사 } 의 종속성이 존재하는 것 처럼 보였지만, 동일한 슈크림 빵을 상품이름으로 사용하는 제조사 B의 상품이 추가됨에 따라 X{ 상품이름 } → Y { 제조사 } 의 종속성은 성립하지 않게 되는 것이다.
- 테이블의 스키마를 정의하는 과정에서 Attribute를 테이블에서 중복된 값을 가질 수 없도록 하는 속성인 Unique 로 설정함으로 명시적으로 해당 속성을 X ( 결정자 ) 로 지정할 수 있다.
- 어떤 제약일까? => X 값에 따라 Y 값이 유일하게 결정되는 X, Y 집합을 얘기한다.[X는 결정자, Y는 종속자 이다.]
[ 📜 Functional Dependency e.g. ]
case1. anomaly의 사용자 테이블 ( 로그인 아이디와 닉네임은 non-null 이며 1개의 값만 가지고, 중복이 불가능 하다. )
- { 사용자ID } → { 로그인ID } == True,
- { 사용자ID } → { 그룹이름 } == False. 그룹이 없는 사용자도 있을 수 있고, 2개 이상의 그룹에 들어있는 사용자가 있을 수 있는데, FD는 X로 인해 유일하게 결정되어야 하므로 로그인ID와 그룹이름은 FD관계가 아니다.
그 외 Functional dependency(FD) 예시
- { stu_id, class_id } → { grade }
- { bank_name, bank_account } → { balance }
🚨 테이블에 Attribute Y는 언제나 하나의 값만 가지는 경우 { } → Y 가 성립한다.
- 테이블 자체에 종속성을 지닌다고 이해하면 좋을 것 같다.
[ Functional Dependency 의 종류 - trivial FD, non - trivial FD, partial FD, full FD ]
❓FD 를 여러 종류로 구분하는 것은 정규화가 일련의 과정으로 이루어 지기 때문에 효율적인 정규화 절차를 위해서 구분 한다. → e.g. BCNF 는 모든 유효한 non - trivial FD 를 토대로 정규화가 이루어지는 정규형이다.
Trivial FD
- X → Y 일 때, Y가 X의 부분 집합일 경우, 해당 FD 는 trivial FD 이다.
- { a, b } → { a }
- { a, b } → { b }
- { a, b } → { a, b }
Non - Trivial FD
- X → Y 일 때, Y 가 X의 부분 집합이 아닐 경우, 해당 FD 는 non - trivial FD 이다.
- { a, b } → { b, c }
- { a, b } → { c }
Partial FD
- X → Y 일 때, Y가 X의 부분집합 만으로도 Y 값이 결정이 될 수 있을 경우, 해당 FD는 Partial FD 이다.
- { stu_id, stu_name } → { email } ➡️ stu_id 만으로도 email 정보를 가져올 수 있다.
Full FD
- X → Y 일 때, Y가 결정되기 위해서는 X의 모든 속성이 필요할 경우, 해당 FD는 Full FD 이다.
- { row, column } → { cellData } ➡️ excel의 특정 셀의 값을 얻기 위해서는 행, 렬의 정보가 필요하다.
FD는 더불어 데이터베이스 설계, 정규화 과정에서 반드시 필요로 하는 개념인 Attribute의 세부 속성과 Key에 대한 개념도 학습해보자.
Key, Attribute 세부 속성 ( super key, candidate key, primary key ) ( prime Attribute, non - prime Attribute )
🌟 FD 는 데이터 베이스 설계에서 속성들 간의 의존 관계를 나타내는 개념이라면, Key 와 Attribute 세부 속성은 테이블 내에서 각 튜플을 어떻게 식별하고 구성하는지 하는지를 다루어 데이터의 고유성과 식별성을 유지하는 데 중점을 두는 개념이다.
[ Key 예시 ]
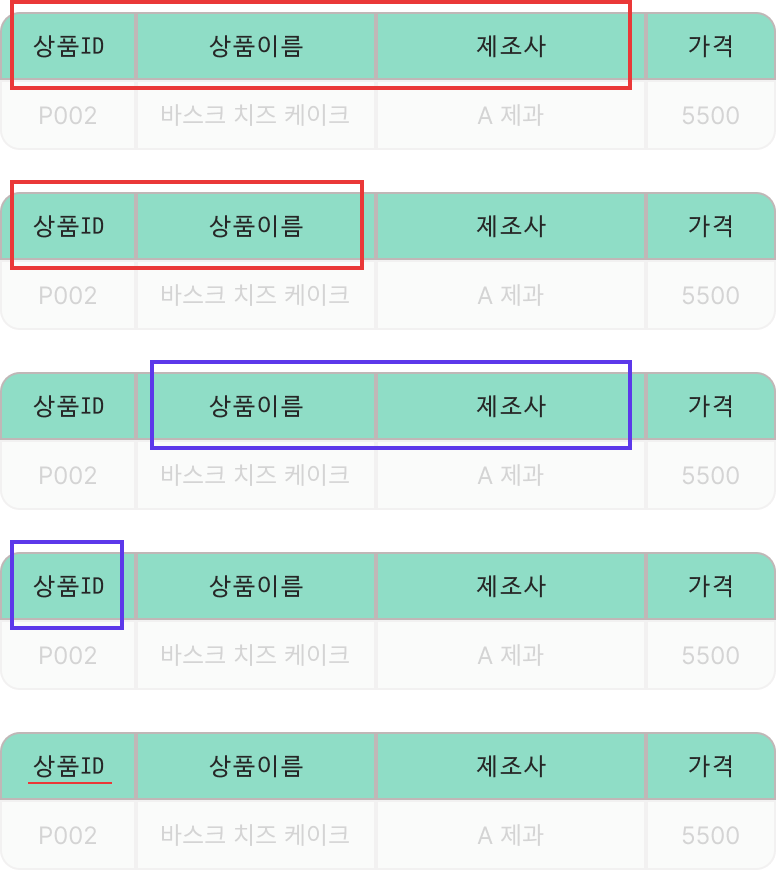
🟥 Super Key
- 테이블에서 한 tuple 을 유일하게 식별할 수 있는 속성또는 속성들의 집합을 말한다.
- 슈퍼키는 유일성을 보장하지만, 최소성을 보장하지는 않는다.
- e.g. { 학번 } 만으로도 학생의 이메일을 유일하게 식별하는 것을 보장하지만, { 학번, 이름, 생년월일 } 과 같이 불 필요한 속성이 포함된 집합도 슈퍼 키가 될 수 있다.
🟦 Candidate Key
- 슈퍼 키 중에서 최소성을 만족하는 키를 후보키 라고 한다. 후보 키는 테이블에서 튜플을 유일하게 식별하면서도, 불필요한 속성이 포함되지 않은 최소한의 속성 집합이다.
- '후보'를 생략하고 키 라고 하기도 한다.
- { 학번 } 과 { 주민등록 번호 } 는 학생을 유일하게 식별할 수 있으며, 각각이 최소성을 갖춘 속성 집합이므로 후보 키가 될 수 있다.
- 모든 후보 키는 슈퍼 키이다 ==> ⭕
Primary Key ( Attribute 에 밑줄을 그어 표기 하는 방식 사용. )
- 테이블에서 tuple을 유일하게 식별하기 위해 선택된 후보 키
- 하나의 테이블에는 하나의 Primary Key만 존재할 수 있다.
Prime Attribute
- 후보 키의 일부에 속하는 개별 속성들을 Prime Attribute 이라고 한다.
non - Prime Attribute
- 후보 키에 포함되지 않은 속성들을 Non - prime Attribute 이라고 한다.

[ A. 오늘 복습한 내용 / B. 다음에 학습할 내용 ]
A. X
B. 정규화 단계 정리
[Reference]
[ FD ]
[ anomaly ]
10-1. Update anomaly, Function Dependency과 Relation Decomposition
세심하지 못하게 짜려진 데이베이스 디자인은 갱신 이상(Update anomalies)을 겪어 컨트롤할 수 없는 데이...
blog.naver.com
'웹개발 - Back 관련 > RDBMS' 카테고리의 다른 글
| [DB] DB 관리 시스템 (DBMS) - DBMS 개요와 RDBMS, NoSQL (0) | 2024.08.27 |
|---|
